
This is the first post after a long hiatus from active blogging. Having spent the past nearly 3+ years running a tech – (all of product, data and engineering) – team out of Bangalore, I have learnt much as how things are evolving in India and hopefully will get the opportunity to share the same on this thread. In the meanwhile, over the past couple of weeks, I have spent some time looking at the whole evolution in ML, AI and its sister disciplines over this time frame, just to baseline myself. Shown below is a proxy indicator for “popularity” of these terms over this time period (Please click on the image for a magnified view).
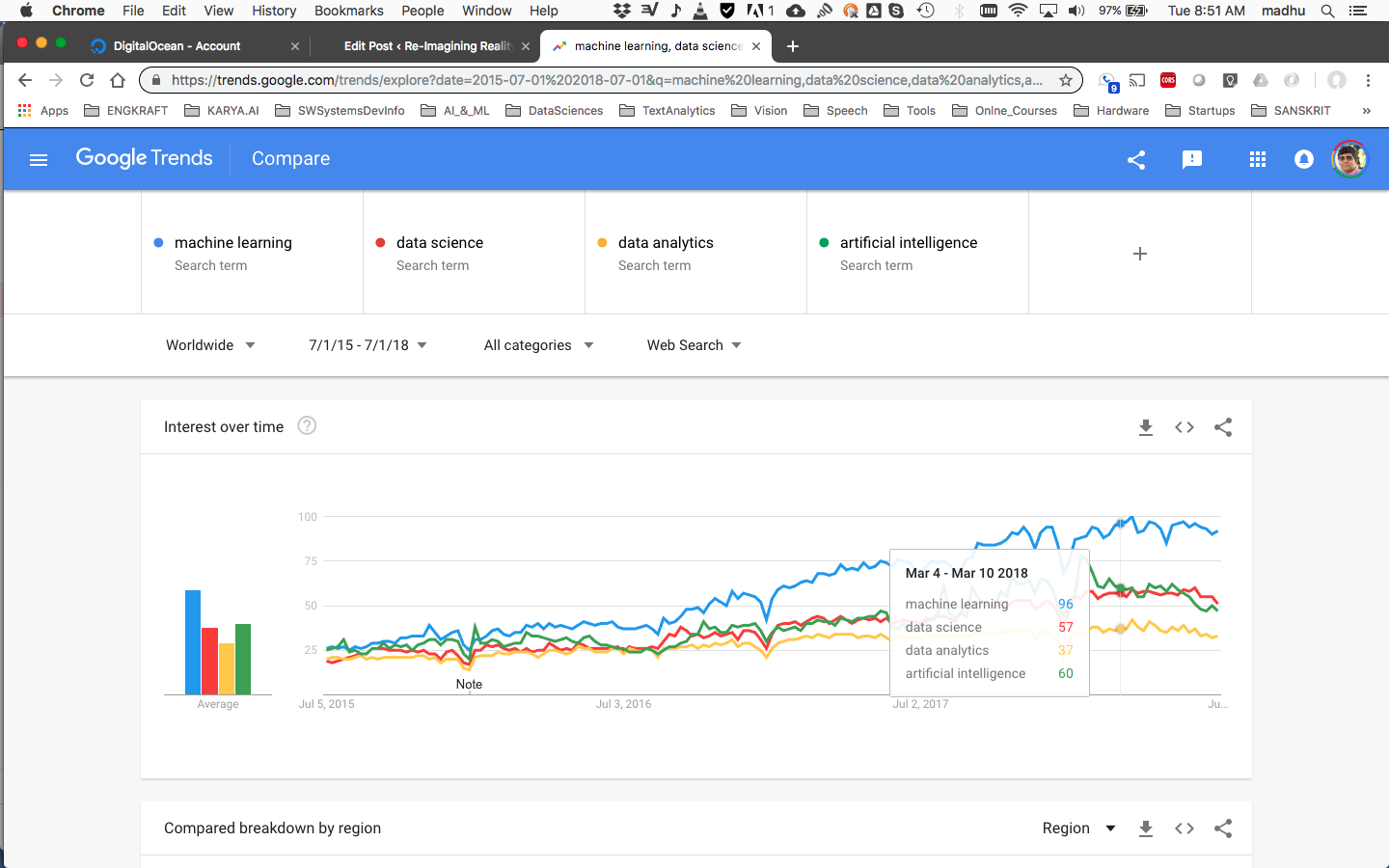
Overall, these trends suggest lots of activity in the “enabling with AI” space across many application domains. One key thing to note is the downward trend in these graphs over the past quarter. Is this a leading indicator of things to come? Too early to call. As things stand, everyone in tech is doing some sort of ML or data science or wants to do something with data. We have also seen lots of venture funding and a lot of innovation, entrepreneurial and tech activity over this time frame.
Firstly, what good things have come out during this period (perhaps my biased view) ?
- Deep Learning as a viable tool in the AI toolkit – lots of libraries, custom built hardware – chips and GPUs, a better understanding of where it works – image/video processing, speech, text – and where it does not and a much clearer focus on what are the really hard problems to focus on, the need for explainability, the costs of compute doing data intensive AI etc. The key thing about this journey is a better understanding of the complexities of building AI systems – even for R&D purposes.
- Improvements in Basic Modeling around Causality – For those who have been following the research around Uncertainity and AI – the basic structuring and formalization of Causality is a key first step in building complex reasoning systems. We finally have some kind of scaffolding to reason with data and build more reliable “chunks” of knowledge. Deterministic and Probabilistic/data-driven knowledge may be combined effectively.
- Automated Driving and other applications of AI – as folks in a variety of domains adopt AI/machine intelligence etc. More experimentation with the tools of AI builds an awareness and experience of the complexities of AI. Domains of application range from agriculture, computational in-silico biology, health care to many more.
- Improvements in hardware – Availability of advanced chips, custom compute/data acquisition devices, sensors, chips for signal/image/speech processing, drone technologies, cheaper/smaller/energy efficient data/power storage tech., have made many real world problems tractable in an engineering sense. Investments required to build heterogeneous platforms to solve realworld problems are reasonable. AI systems can utilize these platforms for data/knowledge acquisition and interaction with other systems and users. Improvements in components, communication devices, mechanisms, new materials etc. are driving advances in different kinds of “robotic” – aka mechatronic systems. What is a robot versus a “mechatronic” system ? the boundary between these two categories is the amount of autonomy that the system has embedded in it.
- AI – software toolkit “commoditization” – Advances in AI toolkits, development libraries, Cloud infra – AWS, GCP, Azure – has helped teams focus on building the intelligence. SW systems engineering is a minor issue in the basic proof-of-concept phase of the product development lifecycle. Teams can focus on “capturing” and modeling the intelligence as SW has matured to a reliable point. AI APIs help one at least evaluate the viability of an idea.
- Latent Commercial Potential – Embedding intelligence in any process promises a variety of economic and related benefits – either for a consumer or an enterprise. Under the rubric of AI for the Enterprise – a number of initiatives are being pursed such as – 1) the advent of “chatbot” technology/platforms for intra and inter-organizational activities, 2) advanced data exploration and visualization technologies – as enterprises focus on exploiting data for better decision-making , 3) Investments in Big data infrastructure and teams – as companies seek a better understanding of how to use AI technologies internal and external to an organization. Much of this has been driven by expanding consumer expectations – (driven by advanced voice/speech/video technologies) – and due to the availability of large amounts of proprietary data – internally and externally in organizations. Also, large scale AI R&D has moved to quasi-commercial and commercial entities rather than being purely academic (such as the Allen Institute and others), and the Chinese (private + public) initiatives.
However, there are a few key issues, that are yet to addressed in a concrete manner and only slowly being understood. These are :-
- Misunderstanding the Role of Data versus Role of Knowledge in building Intelligent Systems – This is a very important problem. Current ML/Deep learning driven approaches implicitly believe – given enough data in any domain, “black-box” systems can be learnt. The primary motivation for the rise in ML-based systems was the reason that “knowledge” need not be painfully encoded into a system but can be seamlessly learnt from data. Since it is learning from data, the system will be less brittle. Unfortunately, as folks are realizing even data-driven systems are highly brittle – they are “knowledge weak” – and one does not even know where. So where do we go from here ? How do be we build systems that accommodate both and evolve as each type of “knowledge” evolves ? It is also important to remember that when we identify something as “data” – there is an implicit model behind it. For example, even a “concept” such as an “address” – has a mental model – aka knowledge. Additionally, intelligence can be encoded in the “active agent” or in the environment or a combination of both. For example, guidance strips to help AGVs navigate on the shop floor is structuring the environment. Building a more general purpose AGV that uses LIDAR and sensors is encoding intelligence in the active agent. It is apriori unclear what should be done with respect to these choices in most domains.
- Complexity of Collecting Data and Ground Truth for different phenomena – Most supervised learning approaches need data collection at scale. Also required is labelled data at scale which is of reasonably high quality. Developing a viable approach to do this is a highly iterative process. Crowd-sourcing approaches only help so much – may be they are good for “common-sense” tasks, but may be totally infeasible for “specialized” tasks – where background knowledge is required. How does one apriori know what kind of approach should one take – purely data driven versus knowledge driven ? What kind of “knowledge gathering” activities should one do?
- Engineering without the Science – – the growing divide – Capturing intelligence from data – as models/rules etc and validating them for stability/robustness etc is an extremely difficult problem. Engineering as I mentioned is the easy part. In most organizations, engineering progress can be shown with minimal effort whereas data science/AI work takes time. The organizational divide that is engendered by this is a major issue. It is important to realize that without the intelligence in a domain codified, driving your product evolution based on engineering metrics is counter productive.
- Are we setting ourselves for an AI winter or AI ice-age ? – With the amount of buzz in popular media around AI technologies and the huge investments being made, it is unclear if time horizons to solve these problems are being estimated properly. We have started seeing signs of major failures in many domains, but these are early days. Both optimists and pessimists abound but the reality is somewhere in-between. There is much we still do not know and have yet to discover – what is intelligence ? how is it in biological systems? How is it to be captured and engineered in artificial systems? How is intelligence defined/modeled for an individual versus for a group ? How does intelligence evolve ? and many more. As society embarks on this quest – it is important that we do not throw out the baby with the bathwater – we do not even recognize the baby – in many of these situations. However, one thing is certainly clear – as things stand – we understand very little about “intelligence” – human or otherwise. Our understanding about intelligence will evolve considerably over the coming years and in the process – we will build systems – some successful/some not so much.
The aforementioned issues have been around from the early days of AI (since the 1950s) and the core issues around understanding the brain, modeling cognition (Does it even take place in the brain?), knowledge representation, Is one kind of knowledge enough for a task, How do measure/evaluate intelligence etc. require further basic research. Progress in basic research has been slow as the problems are extremely difficult. Applied AI may be on the right path but much engineering needs to be done – many systems need to be built in many domains and lessons learnt. However, this collective quest to build AI systems – may finally drive us to focus on problems of real value and real impact in the long run. It is not yet too late to join the journey. Every problem worth solving is still being looked at! More on these problems in upcoming blog entries.